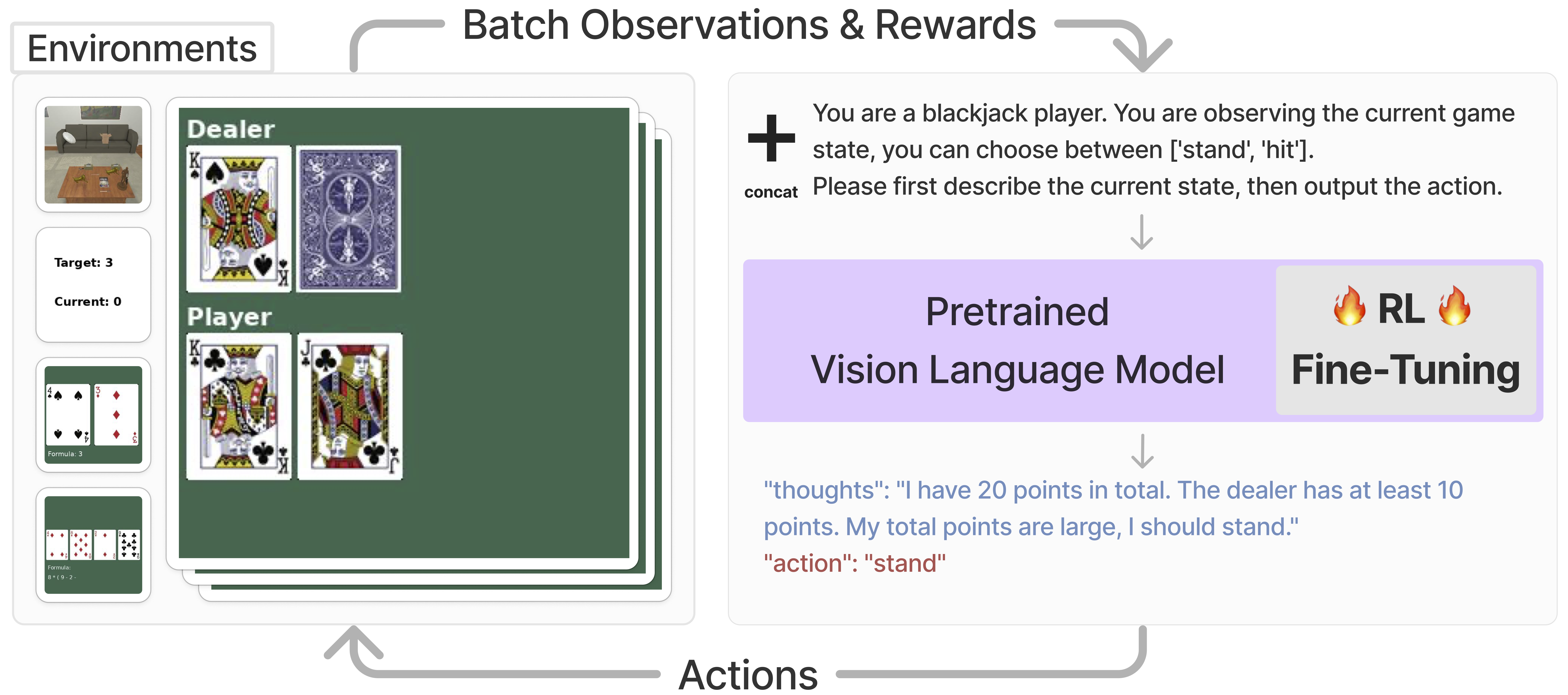
We propose a Reinforcement Learning (RL) training framework for
large Vision Language Models (VLM) or Multimodal Large Language Models (MLLM)
using task-specific rewards. At each time step, the VLM takes the current observation
and a system prompt as inputs and outputs a formatted utterance containing a
chain of thought reasoning
and a text action. The action is parsed and mapped to the
environment producing a reward. We then apply RL with the task reward to fine-tune the VLM.
Training VLMs with RL
We propose an algorithmic framework that directly fine-tune a large vision-language model (VLM)
or Multimodal large language model (MLLM) using Reinforcement Learning (RL), using task rewards.
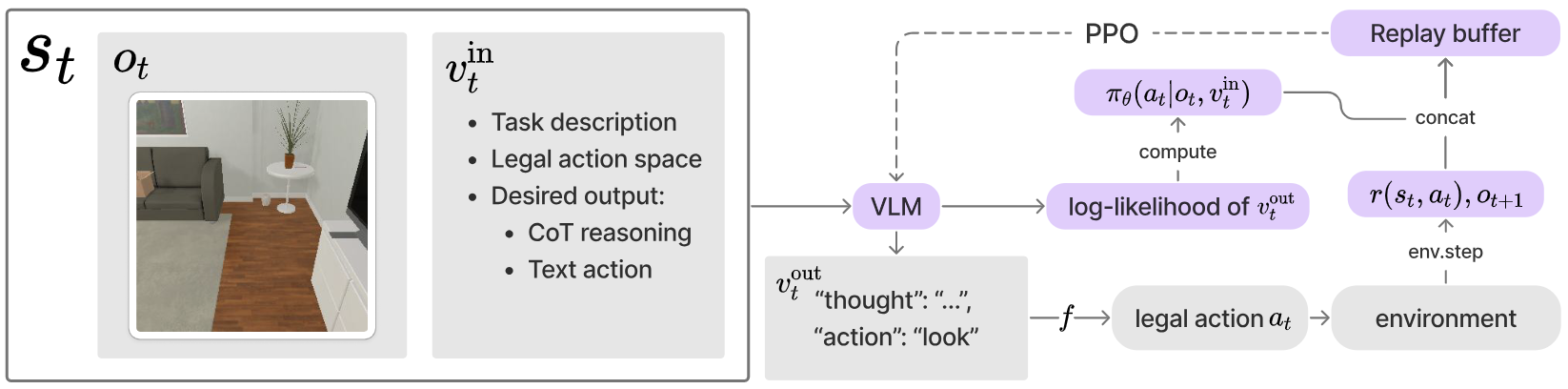
An overview of our RL training framework for VLM. Our method contains three key components:
(1) Designing the input prompt $v_t^\text{in}$, for obtaining a formatted output $v_t^\text{out}$;
(2) Post-processing the output text $v_t^\text{out}$ for a legal action $a_t$;
(3) Estimating the action probability $\pi_\theta(a_t|o_t,v_t^\text{in})$.
Designing the input prompt $v_t^\text{in}$
We design a $v_t^\text{in}$ in the following format, containing (1) task description; (2) legal action space;
and (3) the desired output format $v_t^\text{out}$(containing the CoT reasoning).
Task-specific CoT prompt input $v_t^\text{in}$, where the blue part
represents the CoT reasoning and the red part is the text-based action.
Post-processing the output text $v_t^\text{out}$
We post-process the output text $v_t^\text{out}$ by directly searching for the keywords of
"action": "$a$", where $a\in\mathcal{A}$ is the text version of a legal action.
If the output text $v_t^\text{out}$ does not contain a legal action,
we perform random exploration in the legal action space.
\begin{equation}
f(v^\text{out}) = \begin{cases}
a,& \text{if } \texttt{"}\mathtt{action}\texttt{"}: \texttt{"}a\texttt{"}\in v^\text{out},\\
\mathtt{Unif}(\mathcal{A}),& \text{otherwise.}
\end{cases}
\end{equation}
Estimating the action probability $\pi_\theta(a_t|o_t,v_t^\text{in})$
A naive way to compute the log action probability $\log \pi_\theta(a_t|o_t,v_t^\text{in})$ is to
directly sum up the log probability of each token in $v_t^\text{out}$ via:
\begin{equation*}
\log\pi_\theta(a_t|o_t,v_t^\text{in})\leftarrow\log \pi_\theta({\color{#6C8EBF} v^\text{tht}_t}|o_t,v^\text{in}_t) + \log \pi_\theta({\color{#B85450} v^\text{act}_t}|o_t,v^\text{in}_t,v^\text{tht}_t).
\end{equation*}
However, since our method directly parse the action tokens ${\color{#B85450} v^\text{act}_t}$ to obtain
the legal action $a_t$, and the CoT tokens ${\color{#6C8EBF} v^\text{tht}_t}$ are generally much longer
than the action tokens ${\color{#B85450} v^\text{act}_t}$, we adopt a regularized version that scale down
the log probability of the CoT tokens ${\color{#6C8EBF} v^\text{tht}_t}$ by a factor $\lambda\in[0,1]$,
which results in:
\begin{equation*}
\log\pi_\theta(a_t|o_t,v_t^\text{in})\leftarrow\lambda \log \pi_\theta({\color{#6C8EBF} v^\text{tht}_t}|o_t,v^\text{in}_t) + \log \pi_\theta({\color{#B85450} v^\text{act}_t}|o_t,v^\text{in}_t,v^\text{tht}_t).
\end{equation*}
We found that choosing a moderate value of $\lambda$ (e.g., $\lambda\in[0.2,0.5]$) works well in practice.
Evaluation Tasks
GymCards
Our GymCards environment is designed to evaluate VLMs' arithmetic capabilities
using visual perception and language reasoning in deterministic and stochastic tasks.
More precisely, tasks in the GymCards domain require the VLM to recognize the numbers
(potentially from cards) and utilize the numbers for reasoning.
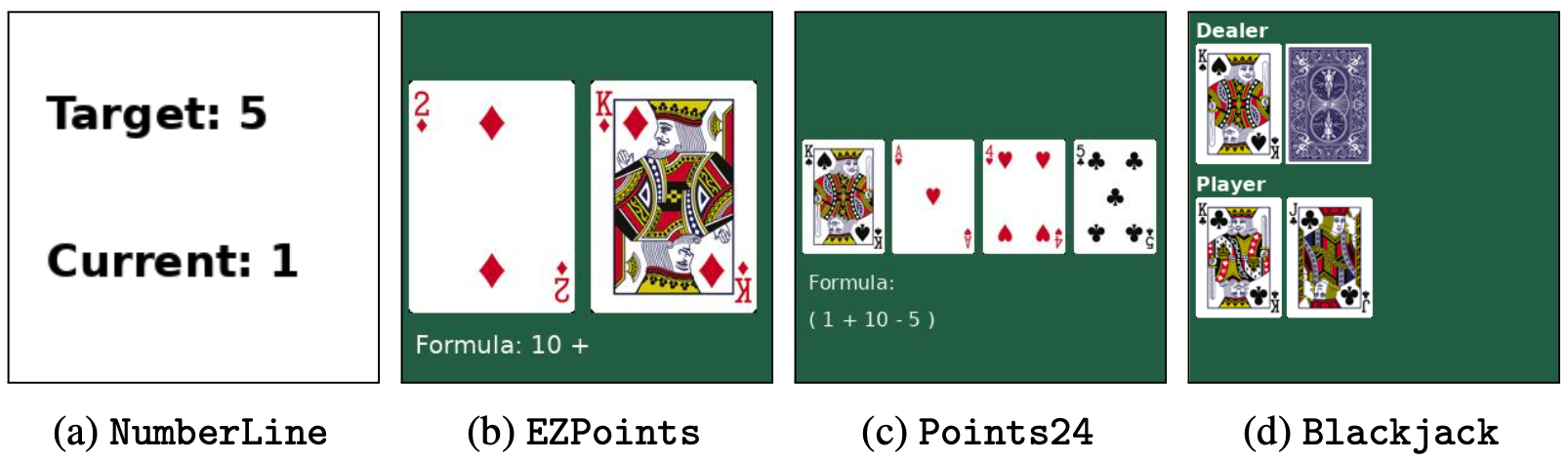
Visualization of a state of tasks in the card environments. From left to right: Numberline, Blackjack, EZPoints, and Points24.
Goals
NumberLine. Move the current number to the target number by adding or subtracting 1 from the current number.
EZPoints. Generate an equation that equals 12, using the 2 numbers from the cards ('J'. 'Q', and 'K' are treated as '10').
Points24. Generate an equation that equals 24, using the 4 numbers from the cards ('J'. 'Q', and 'K' are treated as '10').
Blackjack. Win the current game by choosing "hit" or "stand".
Examples of Transitions in the GymCards Environment
Examples of transition in our GymCards environment.
AlfWorld
We also adopt the ALFWorld environment, to evaluate VLM's
decision-making capabilities in tasks that require visual semantic understanding. See an example of the
ALFWorld environment below.
An example of transition in the ALFWorld environment.
We show that our method can enable a backbone LLaVA-1.6-7b
model to outperform commercial models (GPT4-V
and Gemini), and supervised fine-tuned LLaVA-7b.
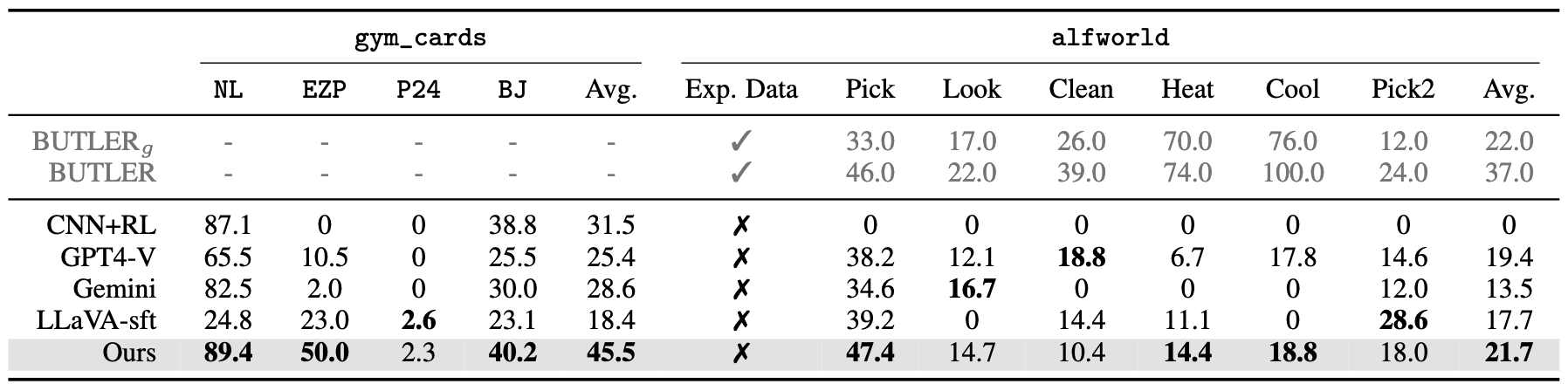
The average episode success rate of our method compared against other methods.
Our method achieves the best overall performance in both GymCards and ALFWorld
(without expert data) environments.
The average episode success rate of our method compared against other methods.
The curves of Points24 are not provided because no method achieves a reasonable performance.
The importance of CoT reasoning
We demonstrate that the CoT reasoning is a crucial component of our method --
the performance of our method significantly deteriorates without the CoT reasoning.
The average episode success rate of our method with
and without the CoT reasoning.
The average episode success rate of our method with
and without the CoT reasoning.
The curves of Points24 are not provided because no method achieves a reasonable performance.
BibTeX
@inproceedings{zhai2024finetuning,
title={Fine-Tuning Large Vision-Language Models as Decision-Making Agents via Reinforcement Learning},
author={Zhai, Yuexiang and Bai, Hao and Lin, Zipeng and Pan, Jiayi and Tong, Shengbang and Zhou, Yifei and Suhr, Alane and Xie, Saining and LeCun, Yann and Ma, Yi and Levine, Sergey}
booktitle={The Thirty-eighth Annual Conference on Neural Information Processing Systems},
year={2024},
url={https://openreview.net/forum?id=nBjmMF2IZU}
}
Acknowledgment
Website template is taken from here.
We thank the Hyperbolic Labs for the generous compute support.